

اگر پردازنده (CPU) را مغز متفکر و مدیرعامل سیستم بدانیم، کارت گرافیک (GPU) دپارتمان هنر و کارخانه تصویرسازی کامپیوتر شماست. در دنیای بازیهای ویدیویی و رندرینگ، داشتن یک پردازنده قدرتمند بدون یک کارت گرافیک مناسب، مانند داشتن یک فیلمنامه شاهکار بدون دوربین فیلمبرداری است. در این مقاله، قصد داریم از سطح پوسته ظاهری کارت گرافیک عبور کنیم و به صورت مهندسی ببینیم در قلب این قطعه چه میگذرد.
در این مقاله میخوانیم:
- تفاوت ساختاری CPU و GPU؛ چرا به هر دو نیاز داریم؟
- برسی قطعات داخلی کارت گرافیک
- حافظه ویدیویی (VRAM) و پهنای باند
- چرخه رندرینگ (Rendering Pipeline) در یک نگاه
- ارتباط GPU با پدیده گلوگاه (Bottleneck)
- معماری حافظه نهان (Cache) در کارتهای گرافیک؛ فراتر از VRAM
- جادوی رهگیری پرتو: کالبدشکافی ساختار BVH
- سربار درایور و نقش API های سطح پایین (DirectX 12 و Vulkan)
- برسی اجرایی: زمانبندی وارپها (Warp Scheduling) و پردازش ناهمگام
- بیایید به همان اتاق ساکت مهندسی برگردیم:
- نتیجهگیری: سمفونی سیلیکونی در قاب مانیتور شما
تفاوت ساختاری CPU و GPU؛ چرا به هر دو نیاز داریم؟
بزرگترین تفاوت پردازنده مرکزی و پردازنده گرافیکی در نوع معماری آنهاست.
یک مثال ساده: CPU را مانند یک گروه 4 نفره از پروفسورهای ریاضیات (هستههای کم اما به شدت قدرتمند) در نظر بگیرید که میتوانند پیچیدهترین معادلات دیفرانسیل را به نوبت حل کنند. در مقابل، GPU مانند یک استادیوم با 50 هزار دانشآموز دبستانی است که شاید نتوانند انتگرال بگیرند، اما میتوانند به صورت همزمان 50 هزار عمل جمع و تفریق ساده را در یک ثانیه انجام دهند!
به این شیوه کار در GPU، پردازش موازی (Parallel Processing) میگویند. رندر کردن یک تصویر 4K نیازمند محاسبه رنگ و نور برای بیش از 8 میلیون پیکسل (2160 *3840 ) در کسری از ثانیه است؛ کاری که فقط از دست لشکر عظیم هستههای گرافیکی برمیآید.
برسی قطعات داخلی کارت گرافیک
وقتی به مشخصات فنی یک کارت گرافیک نگاه میکنید، با اصطلاحات مختلفی روبرو میشوید. بیایید معماری داخلی یک GPU مدرن را تشریح کنیم:
- هستههای پردازشی (CUDA Cores در انویدیا / Stream Processors در AMD): اینها همان دانشآموزان مثال ما هستند. واحدهای محاسباتی پایهای که وظیفه اصلی رسم هندسه و سایهزنی پیکسلها را بر عهده دارند. هرچه تعدادشان بیشتر باشد، توان خام کارت گرافیک بالاتر است.
- هستههای رهگیری پرتو (RT Cores): در گذشته، نورپردازی بازیها به صورت از پیش تعیین شده (Bake شده) بود. اما هستههای RT وظیفه محاسبه فیزیکی مسیر نور، بازتابها و سایهها را به صورت درنگزمان (Real-Time) بر عهده دارند. محاسبات Ray Tracing به قدری سنگین است که اجرای آن روی هستههای معمولی CUDA باعث افت شدید فریم میشود.
- هستههای تنسور (Tensor Cores / AI Accelerators): این هستههای تخصصی برای محاسبات ماتریسی و یادگیری ماشین (Machine Learning) طراحی شدهاند. تکنولوژیهای انقلابی مثل DLSS انویدیا مستقیماً توسط همین هستهها اجرا میشوند تا فریمریت شما را بدون افت کیفیت تصویر، افزایش دهند.

حافظه ویدیویی (VRAM) و پهنای باند
کارت گرافیک برای دسترسی سریع به بافتها (Textures)، مدلهای سهبعدی و فریمهای در حال رندر، به حافظه فوقسریع و اختصاصی خودش نیاز دارد که به آن VRAM میگویند. اما حجم VRAM تنها نیمی از ماجراست؛ نیمه مهمتر، پهنای باند (Bandwidth) است.
پهنای باند مشخص میکند که در هر ثانیه چه مقدار داده میتواند بین تراشه گرافیکی و حافظه VRAM جابجا شود. این مقدار از طریق فرمول زیر محاسبه میگردد:
Bandwidth=(Memory Speed×Bus Width)/8
برای بازی کردن در رزولوشنهای 1440p و 4K، استفاده از تکسچرهای باکیفیت به شدت وابسته به پهنای باند بالا و حجم کافی حافظه VRAM است تا سیستم دچار افت فریمهای ناگهانی نشود.
چرخه رندرینگ (Rendering Pipeline) در یک نگاه
برای اینکه یک فریم از بازی روی مانیتور شما نقش ببندد، این چرخه در کسری از ثانیه طی میشود:
- دستورات ترسیم (Draw Calls): پردازنده (CPU) به GPU میگوید چه چیزی باید در صحنه قرار گیرد.
- پردازش هندسی (Geometry Setup): اسکلتبندی سهبعدی اجسام (پلیگانها و ورتکسها) شکل میگیرد.
- رسترایزیشن (Rasterization): مدلهای سهبعدی (وکتورها) روی یک صفحه دوبعدی تخت میشوند و به شبکهای از پیکسلها تبدیل میگردند.
- سایهزنی (Shading): رنگ، بافت و نور به تکتک پیکسلها اعمال شده و تصویر نهایی آماده ارسال به مانیتور میشود.
ارتباط GPU با پدیده گلوگاه (Bottleneck)
در مقاله جامع گلوگاه چیست، توضیح دادیم که گلوگاه زمانی رخ میدهد که یکقطعه نتواند همپای قطعه دیگر کار کند. خود در حال پردازش گرافیکی باشد و پردازنده زمان کافی برای تغذیه آن را داشته باشد.
در دنیای ایده آل گیمینگ، ما همیشه به دنبال وضعیت TGPU>TCPU هستیم (که در آن T نماد زمان است). یعنی کارت گرافیک با توان خود در حال پردازش گرافیکی باشد و پردازنده زمان کافی برای تغذیه آن را داشته باشد.
هنگامی که رزولوشن بازی را از 1080p به 4K افزایش میدهید، فشار محاسبات پیکسلها به شدت بالا میرود و گلوگاه به صورت طبیعی و دلخواه، روی GPU میافتد که به معنای استفاده حداکثری از پولی است که برای کارت گرافیک پرداختهاید!
معماری حافظه نهان (Cache) در کارتهای گرافیک؛ فراتر از VRAM
شاید فکر کنید تنها حافظه مهم در کارت گرافیک، همان VRAM است؛ اما مهندسان انویدیا و AMD رازی در آستین دارند به نام کش (Cache).
راحت تر میتونیم برسسیش بکنیم اینطور در نظر بگیرید که اگر VRAM انبار مواد غذایی در زیرزمین رستوران باشد، حافظه کش (L1 و L2) همان میز کار سرآشپز است که مواد ضروری دقیقاً روی آن قرار دارند. رفتن به انبار زمانبر است، اما برداشتن چاقو از روی میز در کسری از ثانیه انجام میشود.
در معماریهای جدید (مثل سری RTX 40 انویدیا یا RDNA در AMD)، حجم حافظه L2 Cache و L3 Cache (که AMD به آن Infinity Cache میگوید) به شدت افزایش یافته است. از نظر مهندسی، هر بار که پردازنده گرافیکی دادهای را در کش پیدا کند (پدیدهای که به آن Cache Hit میگویند)، دیگر نیازی به درگیر کردن باس اصلی حافظه ندارد. این یعنی صرفهجویی عظیم در مصرف انرژی و دور زدن محدودیتهای فیزیکی پهنای باند.

جادوی رهگیری پرتو: کالبدشکافی ساختار BVH
وقتی از Ray Tracing یا رهگیری پرتو صحبت میکنیم، پردازنده گرافیکی باید مسیر میلیونها پرتو نور و برخورد آنها با اشیاء صحنه را محاسبه کند. اگر قرار باشد کارت گرافیک برخورد هر پرتو را با تکتک پلیگانهای صحنه چک کند، حتی قدرتمندترین کارتها هم ذوب میشوند!
اینجا پای یک مفهوم ریاضی و مهندسی به نام BVH (Bounding Volume Hierarchy) به میان میآید. BVH اشیاء داخل بازی را در جعبههای نامرئیِ تودرتو دستهبندی میکند.
فرض کنید کلیدتان را در خانه گم کردهاید. به جای اینکه وجب به وجبِ کل خانه را بگردید، اول میگویید کلید در اتاق خواب است، بعد میگویید داخل کمد است، و در نهایت داخل کشوی اول است.
ساختار BVH پیچیدگی محاسبات تقاطع پرتو را از حالت خطی O(n) به حالت لگاریتمی O(logn) کاهش میدهد. هستههای RT به صورت سختافزاری دقیقاً برای پیمایش همین درخت BVH و انجام تستهای تقاطع طراحی شدهاند تا فریمریت بازی شما نابود نشود.
سربار درایور و نقش API های سطح پایین (DirectX 12 و Vulkan)
کارت گرافیک برای اینکه بداند چه چیزی را باید رندر کند، منتظر دستورات CPU میماند. این دستورات از طریق رابطهای برنامهنویسی (API) مانند DirectX یا Vulkan ترجمه و ارسال میشوند.
در نسلهای گذشته (مثل DirectX 11)، ارسال دستورات گرافیکی (Draw Calls) فقط روی یک هسته از CPU انجام میشد. این یعنی حتی اگر پردازنده شما 16 هسته داشت، کارت گرافیک باید منتظر یک هسته میماند تا لیست کارها را بفرستد که به این پدیده API Overhead میگویند.
در DirectX 12 و Vulkan، معماری تغییر کرد. حالا CPU میتواند از طریق چندین هسته به صورت موازی Command List (لیست وظایف) بسازد و همزمان به کارت گرافیک بفرستد. این ارتباط سطح پایین، تاخیر را کاهش داده و باعث میشود استریم دادهها روانتر صورت گیرد.
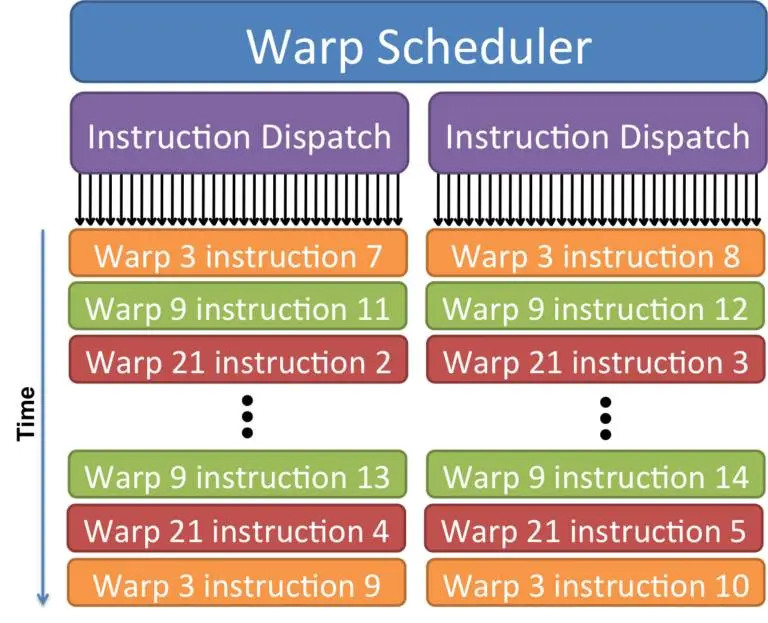
برسی اجرایی: زمانبندی وارپها (Warp Scheduling) و پردازش ناهمگام
در معماری پردازندههای گرافیکی، هستهها به تنهایی کار نمیکنند، بلکه در گروههایی به نام Warp (در ادبیات انویدیا، معمولاً شامل 32 رشته) یا Wavefront (در معماری AMD، شامل 32 یا 64 رشته) دستهبندی میشوند.
بیایید به همان اتاق ساکت مهندسی برگردیم:
تصور کنید کارت گرافیک شما در حال رندر یک صحنه شلوغ است. ناگهان یک Warp برای دریافت اطلاعات تکسچر از VRAM باید چند نانوثانیه صبر کند. در دنیای پردازش، چند نانوثانیه یعنی یک عمر بیکاری! اینجاست که Warp Scheduler (زمانبند سختافزاری) وارد عمل میشود. او بدون اتلاف حتی یک سیکل کلاک، فوراً یک Warp دیگر که اطلاعاتش آماده است را جایگزین میکند. این سوئیچ کردن در GPU ها برخلاف CPU تقریباً در صفر ثانیه (ns0) انجام میشود. این یعنی هستههای گرافیکی هرگز بیکار نمیمانند.
علاوه بر این، تکنولوژی Async Compute (پردازش ناهمگام) به معماری اجازه میدهد که خطوط لوله رندر گرافیکی و محاسبات ریاضی (مانند فیزیک بازی یا هوش مصنوعی) به صورت همزمان و در فضاهای خالیِ واحدهای پردازشی (Compute Units) اجرا شوند. نتیجه؟ استفاده از سیلیکون در هر لحظه و تزریق فریمهای بیشتر به مانیتور شما.
نتیجهگیری: سمفونی سیلیکونی در قاب مانیتور شما
خب، وقت آن است که از این اتاق تاریک و مهندسی بیرون بیاییم و به دنیای واقعی (پشت کیبورد و مانیتور) برگردیم.
همانطور که با هم دیدیم، کارت گرافیک (GPU) فقط یک تکه پلاستیک و فلزِ نورانی نیست؛ بلکه یک کلانشهرِ مینیاتوری و به شدت منظم است. در این شهر، پردازنده مرکزی (CP) نقش فرمانده را دارد و دستورات اولیه را صادر میکند. سپس، هزاران کارگر خستگیناپذیر (هستههای CUDA یا Stream Processors) با زمانبندی بینقصِ Warpها و بدون هدر دادن حتی یک نانوثانیه، وارد عمل میشوند. آنها بافتها را با سرعت نور از VRAM میخوانند، با معماری BVH پرتوهای نور را شبیهسازی میکنند و در نهایت، جادوی هوش مصنوعی (Tensor Cores) تصاویر را با بالاترین کیفیت برای شما رندر میکند.
تمام این مفاهیم پیچیده مهندسی از خطوط لوله رندرینگ تا پردازش ناهمگام (Async Compute) تنها یک هدف نهایی دارند: تولید روانترین فریمها برای غرق شدن شما در دنیای بازی.
